This guide explains how to design scalable data pipelines in the modern data engineering landscape, covering architecture, tools, ETL vs ELT, real-time processing, and best practices for building reliable data platforms.
Introduction
In today’s era, when every organisation, regardless of size, is concentrating on data for making concrete decisions, building scalable and reliable data pipelines is essential for transforming raw data into meaningful insights.
Businesses rely on multiple sources for generating their database, including applications, IoT devices, APIs, databases, SaaS platforms, and log systems. An effective data pipeline automates the process of collecting, transforming, and using this data for in-depth analysis, machine learning models, or business dashboards.
Modern data engineering focuses on building pipelines that are scalable, reliable, cloud-compatible, and capable of processing both batch and real-time datasets.
Collect
Bring data from many sources.
Ingest
Move it in batch or real time.
Process
Validate, transform, enrich.
Store
Lake, warehouse, or lakehouse.
Consume
Use it in BI, ML, and apps.
What is a Data Pipeline?
A data pipeline is a system that moves data from source systems to analytics tools while applying transformations, validations, and processing logic.
- 1. Data Collection
- 2. Data Ingestion
- 3. Data Processing
- 4. Data Storage
- 5. Data Consumption

Modern Data Pipeline Architecture
A modern architecture usually includes five major layers, each responsible for a specific part of the data journey.
1. Data Sources
There are various systems for generating raw data, including transactional databases, SaaS applications, event streams, APIs, logs, and IoT devices.
Examples: CRM systems, financial systems, marketing platforms, and operational databases
2. Data Ingestion Layer
Batch Ingestion
Data is collected at scheduled intervals.
Examples: nightly ETL jobs, hourly data loads.
- Apache Airflow
- AWS Glue
- Azure Data Factory
Real-Time Streaming
Data is processed immediately as soon as it is generated.
Used in fraud detection, recommendation engines, financial transactions, and IoT analytics.
- Apache Kafka
- Apache Pulsar
- Amazon Kinesis
3. Data Processing Layer
Here, raw data is compiled and classified into useful forms through operations such as data validation, filtering, aggregations, schema transformation, and enrichment from external sources.
- Apache Spark
- Flink
- Databricks
- dbt
4. Data Storage Layer
Data Lakes
Store raw and structured data using platforms like Amazon S3, Azure Data Lake, and Google Cloud Storage.
Data Warehouses
Optimised for analytics using Snowflake, BigQuery, and Redshift.
Lakehouse
Combines lake flexibility with warehouse performance through platforms like Databricks and Delta Lake.
Modern architectures increasingly use lakehouse platforms to unify analytics and machine learning workloads.
5. Data Consumption Layer
Processed data is accessed by business analysts, data scientists, machine learning models, and dashboard tools.
- Power BI
- Tableau
- Looker
- Superset
ETL vs ELT Pipelines
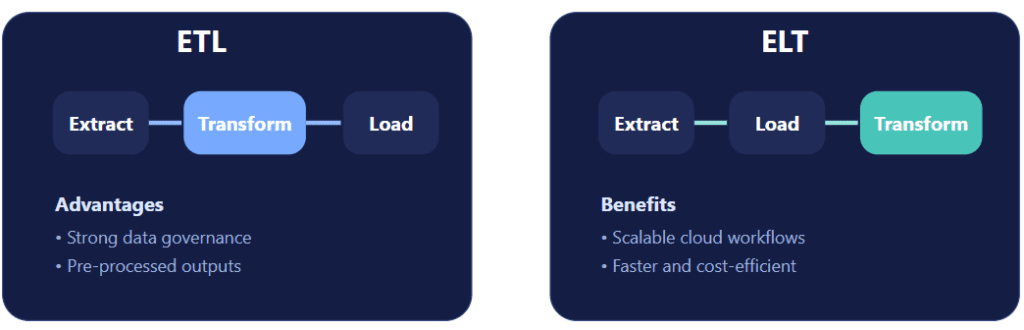
ETL is the traditional pipeline approach: extract data, transform it, and then load it into the warehouse.
Advantages: strong data governance and pre-processed data.
Limitations: slower processing and higher infrastructure complexity.
ELT is more aligned with modern cloud data architecture: extract data, load it into the data lake or warehouse, and transform it there using large-scale compute.
Benefits: scalable, faster processing, and cost-efficient.
Best fit today: Many cloud-native platforms support ELT because modern warehouses and lakehouses provide the compute power needed for scalable in-platform transformation.
Challenges in Designing Data Pipelines
Data Quality
Poor quality data or improper collection directly affects analysis and business decisions.
Solutions: validation checks, schema enforcement, and monitoring.
Scalability
Pipelines must handle increasing data volumes from multiple sources.
Solutions: distributed computing, cloud infrastructure, and auto-scaling clusters.
Pipeline Monitoring
Each pipeline should be monitored to catch issues as early as possible.
Focus on job failures, data latency, throughput, and data freshness.
Strong pipeline design is not only about moving data fast. It is about making the flow dependable, observable, and ready to grow with the business.
Data Governance
Complying with regulatory measures is mandatory for every organisation to secure its data. Important practices include data lineage, access control, and audit logging.
Best Practices for Designing Scalable Data Pipelines
Design for Scalability
Use distributed processing frameworks.
Examples: Spark clusters, Kubernetes, and serverless pipelines.
Implement Data Monitoring
Use monitoring platforms to track pipeline quality and health.
Examples: Monte Carlo, Datafold, and Great Expectations.
Build Modular Pipelines
Break pipelines into reusable components.
Benefits: easier debugging, faster development, and improved reliability.
Automate Workflow Orchestration
Use workflow orchestration tools to manage dependencies across tasks and make complex data flows easier to operate.
- Apache Airflow
- Prefect
- Dagster
Example Modern Data Stack
A simple reference stack for analytics, ML, and real-time use cases
Data Sources → Kafka / API → Spark / Databricks → Delta Lake / Snowflake → Power BI
This type of setup supports reporting, machine learning, and streaming-driven applications at the same time.

Future of Data Pipelines
Modern data pipelines are growing with new capabilities such as AI-driven pipeline automation, real-time analytics platforms, serverless data engineering, data mesh architectures, and autonomous pipeline operations.
- AI-driven pipeline automation
- Real-time analytics platforms
- Serverless data engineering
- Data mesh architectures
- Autonomous, self-healing pipelines
Conclusion
Scalable data pipelines are the backbone of modern data platforms. Organisations that invest in well-designed pipelines will be able to enjoy significant benefits from their data.
With the proper combination of cloud infrastructure, distributed processing, and modern architecture patterns, data engineering teams can build data platforms that are reliable and ready to satisfy future needs.
With the increasing dependency of businesses on data for decision-making, scalable data pipelines will remain an essential component of enterprise technology strategy.
FAQ
What is a data pipeline in data engineering?
A data pipeline is a system that moves and transforms data from source systems to storage or analytics platforms.
What is the difference between ETL and ELT?
ETL transforms data before loading it into storage, while ELT loads raw data first and performs transformations inside the data platform.
What tools are commonly used to build data pipelines?
Popular tools include Apache Kafka, Apache Spark, Databricks, Airflow, and dbt.